Impute pipelines
Imagine having a dataset that you need to use for training a prediction model, but some of the features are missing. The good news is you don't need to throw some data away, just have to impute them. Below are steps you can take in order to create an imputation pipeline.
from random import randint
import matplotlib.pyplot as plt
import mlflow
import numpy as np
import pandas as pd
import seaborn as sns
from hyperopt import fmin, hp, STATUS_OK, tpe, Trials
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import (
ExtraTreesRegressor,
GradientBoostingRegressor,
RandomForestRegressor,
)
from sklearn.impute import SimpleImputer
from sklearn.metrics import mean_squared_error, median_absolute_error
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.tree import DecisionTreeRegressor
sns.()Generate data
Since this is an example and I don't want to get sued by using my company's data, synthetic data it is :) This simulates a dataset from different pseudo-regions, with different characteristics. Real data will be much more varied, but I make it more obvious so it's easy to see the differences.
def generate_array_with_random_nan(lower_bound, upper_bound, size):
a = np.random.(lower_bound, upper_bound + 1, size=size).(float)
mask = np.random.([1, 0], a.shape, p=[0.1, 0.9]).(bool)
a[mask] = np.nan
return a
size = 6000
df_cbd = pd.()
df_cbd["bed"] =(1, 2, size)
df_cbd["bath"] =(1, 2, size)
df_cbd["area_usable"] = np.random.(20, 40, size=size)
df_cbd["region"] = "cbd"
df_suburb = pd.()
df_suburb["bed"] =(1, 4, size)
df_suburb["bath"] =(1, 4, size)
df_suburb["area_usable"] = np.random.(30, 200, size=size)
df_suburb["region"] = "suburb"
df = pd.([df_cbd, df_suburb])
df| bed | bath | area_usable | region | |
|---|---|---|---|---|
| 0 | 2 | 1 | 33 | cbd |
| 1 | 1 | 2 | 23 | cbd |
| 2 | 1 | 2 | 33 | cbd |
| 3 | 2 | 1 | 26 | cbd |
| 4 | 2 | 1 | 28 | cbd |
| 5 | 2 | 2 | 36 | cbd |
| 6 | 1 | 2 | 38 | cbd |
| 7 | 2 | 1 | 23 | cbd |
| 8 | 2 | 1 | 36 | cbd |
| 9 | nan | 2 | 29 | cbd |
Report missing values
I also randomly remove some values to mimic real-world data (read: they are never ready to use), here we will visualize the missing rate of each column.
def report_missing(df):
cnts = []
cnt_total = len(df)
for col in df.columns:
cnt_missing = sum(pd.(df[col]) | pd.(df[col]))
print("col: {}, missing: {}%".(col, 100.0 * cnt_missing / cnt_total))
cnts.({"column": col, "missing": 100.0 * cnt_missing / cnt_total})
cnts_df = pd.(cnts)
sns.(
x=cnts_df.missing,
y=cnts_df.column,
# palette=['r','b'],
# data=cnts_df
)
return sns
(df)col: bed, missing: 10.266666666666667%
col: bath, missing: 9.616666666666667%
col: area_usable, missing: 0.0%
col: region, missing: 0.0%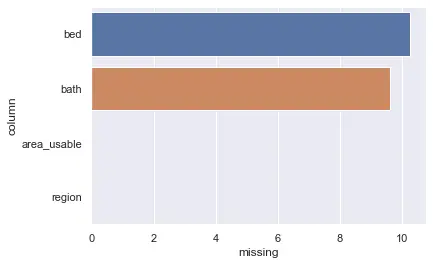
Data exploration
Knowing the missing rate isn't everything, thus it is also a good idea to explore data in other areas too.
## missing bed per region
df[df.bed.()]["region"].(dropna=False)cbd 634
suburb 598
Name: region, dtype: int64## missing bath per region
df[df.bath.()]["region"].(dropna=False)suburb 588
cbd 566
Name: region, dtype: int64## explore region
df.region.()suburb 6000
cbd 6000
Name: region, dtype: int64## explore bed
df.bed.()2.0 4050
1.0 4009
4.0 1393
3.0 1316
Name: bed, dtype: int64## explore bath
df.bath.()1.0 4142
2.0 4022
3.0 1393
4.0 1289
Name: bath, dtype: int64Remove outliers
(wouldn't want your model to have a sub-par performance from skewed data :-P)
## remove outliers hereCreate synthetic columns
In this step, we create percentile, mean and rank columns to add more data points, so the model can perform better :D
First, we find aggregate percentiles for each groupby set, then add mean and rank columns.
synth_columns = {
"bed": {"region_bath": ["region", "bath"]},
"bath": {"region_bed": ["region", "bed"]},
}
for column, groupby_levels in synth_columns.():
for groupby_level_name, groupby_columns in groupby_levels.():
# percentile aggregates
for pctl in [20, 50, 80, 90]:
col_name = "p{}|{}|{}".(pctl, groupby_level_name, column)
print("calculating -- {}".(col_name))
df[col_name] = (
df[groupby_columns + [column]]
.(0)
.(groupby_columns)[column]
.(lambda x: x.(pctl / 100.0))
)
# mean impute
mean_impute = "mean|{}|{}".(groupby_level_name, column)
print("calculating -- {}".(mean_impute))
df[mean_impute] = df.(groupby_columns)[column].("mean")
# bed/bath rank
rank_impute = column_name = "rank|{}|{}".(groupby_level_name, column)
print("calculating -- {}".(rank_impute))
df[rank_impute] = df.(groupby_columns)[column].(
method="dense", na_option="bottom"
)calculating -- p20|region_bath|bed
calculating -- p50|region_bath|bed
calculating -- p80|region_bath|bed
calculating -- p90|region_bath|bed
calculating -- mean|region_bath|bed
calculating -- rank|region_bath|bed
calculating -- p20|region_bed|bath
calculating -- p50|region_bed|bath
calculating -- p80|region_bed|bath
calculating -- p90|region_bed|bath
calculating -- mean|region_bed|bath
calculating -- rank|region_bed|bathCoalesce values
In this step we fill in values obtained from the previous step -- impute time!!
def coalesce(df, columns):
"""
Implement coalesce of function in columns.
Inputs:
df: reference dataframe
columns: columns to perform coalesce
Returns:
df_tmp: pd.Series that is coalesced
Example:
df_tmp = pd.DataFrame({'a': [1,2,None,None,None,None],
'b': [None,6,None,8,9,None],
'c': [None,10,None,12,None,13]})
df_tmp['new'] = coalesce(df_tmp, ['a','b','c'])
print(df_tmp)
"""
df_tmp = df[columns[0]]
for c in columns[1:]:
df_tmp = df_tmp.(df[c])
return df_tmp
coalesce_columns = [
"bed",
"p50|region_bath|bed",
# p50|GROUPBY_LESSER_WEIGHT|bed, ...
]
df["bed_imputed"] =(df, coalesce_columns)
coalesce_columns = [
"bath",
"p50|region_bed|bath",
# p50|GROUPBY_LESSER_WEIGHT|bath, ...
]
df["bath_imputed"] =(df, coalesce_columns)Report missing values (again)
After we impute the values, let's see how much we are doing better!
(df)col: bed, missing: 10.266666666666667%
col: bath, missing: 9.616666666666667%
col: area_usable, missing: 0.0%
col: region, missing: 0.0%
col: p20|region_bath|bed, missing: 0.0%
col: p50|region_bath|bed, missing: 0.0%
col: p80|region_bath|bed, missing: 0.0%
col: p90|region_bath|bed, missing: 0.0%
col: mean|region_bath|bed, missing: 9.616666666666667%
col: rank|region_bath|bed, missing: 0.0%
col: p20|region_bed|bath, missing: 0.0%
col: p50|region_bed|bath, missing: 0.0%
col: p80|region_bed|bath, missing: 0.0%
col: p90|region_bed|bath, missing: 0.0%
col: mean|region_bed|bath, missing: 10.266666666666667%
col: rank|region_bed|bath, missing: 0.0%
col: bed_imputed, missing: 0.0%
col: bath_imputed, missing: 0.0%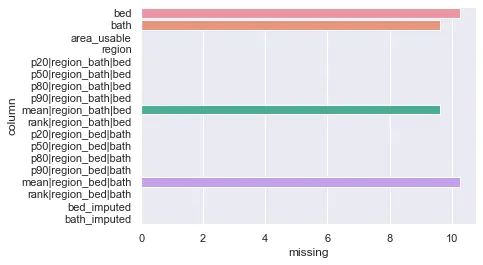
Notice that the imputed columns there are no missing values. Yay!
Assign partition
In this step, we partition the data into three sets: train, dev and test. Normally we only split into train and test set, but the additional "dev" set is there so we can make sure it's not too overfit or underfit.
## assign partition
def assign_partition(x):
if x in [0, 1, 2, 3, 4, 5]:
return 0
elif x in [6, 7]:
return 1
else:
return 2
## assign random id
df["listing_id"] = [(1000000, 9999999) for i in range(len(df))]
## hashing
df["hash_id"] = df["listing_id"].(lambda x: x % 10)
## assign partition
df["partition_id"] = df["hash_id"].(lambda x:(x))## define columns group
y_column = "area_usable"
categ_columns = ["region"]
numer_columns = [
"bed_imputed",
"bath_imputed",
"p20|region_bath|bed",
"p50|region_bath|bed",
"p80|region_bath|bed",
"p90|region_bath|bed",
"mean|region_bath|bed",
"rank|region_bath|bed",
"p20|region_bed|bath",
"p50|region_bed|bath",
"p80|region_bed|bath",
"p90|region_bed|bath",
"mean|region_bed|bath",
"rank|region_bed|bath",
]
id_columns = ["listing_id", "hash_id", "partition_id"]## remove missing y
df = df.(subset=[y_column])
## split into train-dev-test
df_train = df[df["partition_id"] == 0]
df_dev = df[df["partition_id"] == 1]
df_test = df[df["partition_id"] == 2]## split each set into x and y
y_train = df_train[y_column].values
df_train = df_train[numer_columns + categ_columns]
y_dev = df_dev[y_column].values
df_dev = df_dev[numer_columns + categ_columns]
y_test = df_test[y_column].values
df_test = df_test[numer_columns + categ_columns]Create sklearn pipelines
In this step, we chain a few pipelines together to process the dataset for the final time. In this example, we use median followed by standard scalar for numeric columns, and mode followed by encoding labels for categorical columns.
## define pipelines
impute_median =(strategy="median")
impute_mode =(strategy="most_frequent")
num_pipeline =(
[
("impute_median", impute_median),
("std_scaler",()),
]
)
categ_pipeline =(
[
("impute_mode", impute_mode),
("categ_1hot",(handle_unknown="ignore")),
]
)
full_pipeline =(
[
("num", num_pipeline, numer_columns),
("cat", categ_pipeline, categ_columns),
]
)## fit and transform
X_train = full_pipeline.(df_train)
X_dev = full_pipeline.(df_dev)
X_test = full_pipeline.(df_test)X_trainarray([[ 0.04673184, 0.06391404, 0. , ..., -0.16000115, 1. , 0. ],
[-0.97000929, -0.97263688, 0. , ..., -1.01065389,
1. , 0. ],
[ 0.04673184, 0.06391404, 0. , ..., -0.16000115,
1. , 0. ],
...,
[-0.97000929, 1.10046497, 0. , ..., 0.69065159,
0. , 1. ],
[ 0.04673184, 1.10046497, 0. , ..., 0.69065159,
0. , 1. ],
[ 1.06347297, 2.13701589, 0. , ..., 1.54130432,
0. , 1. ]])Hyperparameter tuning
In this step, we try to use different models and parameters to see which performs the best. We utilize mlflow for logging and hyperopt to help with tuning. In this example, we run the trials for 40 iterations, each using a different combination of model and parameters.
## mlflow + hyperopt combo
def objective(params):
regressor_type = params["type"]
del params["type"]
if regressor_type == "gradient_boosting_regression":
estimator =(**params)
elif regressor_type == "random_forest_regression":
estimator =(**params)
elif regressor_type == "extra_trees_regression":
estimator =(**params)
elif regressor_type == "decision_tree_regression":
estimator =(**params)
else:
return 0
estimator.(X_train, y_train)
# mae
y_dev_hat = estimator.(X_dev)
mae =(y_dev, y_dev_hat)
# logging
with mlflow.():
mlflow.("regressor", estimator.__class__.__name__)
# mlflow.log_param("params", params)
mlflow.("n_estimators", params.("n_estimators"))
mlflow.("max_depth", params.("max_depth"))
mlflow.("median_absolute_error", mae)
return {"loss": mae, "status": STATUS_OK}
space = hp.(
"regressor_type",
[
{
"type": "gradient_boosting_regression",
"n_estimators": hp.("n_estimators1", range(100, 200, 50)),
"max_depth": hp.("max_depth1", range(10, 13, 1)),
},
{
"type": "random_forest_regression",
"n_estimators": hp.("n_estimators2", range(100, 200, 50)),
"max_depth": hp.("max_depth2", range(3, 25, 1)),
"n_jobs": -1,
},
{
"type": "extra_trees_regression",
"n_estimators": hp.("n_estimators3", range(100, 200, 50)),
"max_depth": hp.("max_depth3", range(3, 10, 2)),
},
{
"type": "decision_tree_regression",
"max_depth": hp.("max_depth4", range(3, 10, 2)),
},
],
)
trials =()
max_evals = 40
best =(
fn=objective, space=space, algo=tpe.suggest, max_evals=max_evals, trials=trials
)
print("Found minimum after {} trials:".(max_evals))
from pprint import pprint
(best)100%|██████████| 40/40 [00:19<00:00, 2.11trial/s, best loss: 8.569474762575908]
Found minimum after 40 trials:
{'max_depth2': 1, 'n_estimators2': 1, 'regressor_type': 1}Evaluate performance
Run "mlflow server" to see the login dashboard. There, we can see that RandomForestRegressor has the best performance (the less MAE the better) when using max_depth=4 and n_estimators=150, to test the model's performance against another test set:
## use best params on TEST set
estimator =(max_depth=4, n_estimators=150)
estimator.(X_train, y_train)
y_train_hat = estimator.(X_train)
train_mae =(y_train, y_train_hat)
y_dev_hat = estimator.(X_dev)
dev_mae =(y_dev, y_dev_hat)
y_test_hat = estimator.(X_test)
test_mae =(y_test, y_test_hat)
mae = {
"name": estimator.__class__.__name__,
"train_mae": train_mae,
"dev_mae": dev_mae,
"test_mae": test_mae,
}
mae = pd.([mae]).("name")
mae| name | train_mae | dev_mae | test_mae |
|---|---|---|---|
| DecisionTreeRegressor | 8.930245 | 8.592484 | 8.729826 |
You'll notice that we use "median absolute error" to measure performance. There are other metrics available, such as mean squared error, but in some cases it's more meaningful to use a metric that measure the performance in actual data's unit, in this case the error on dev and test set are around 8 units away from its correct value. Since normally we use square meter for area, it means the prediction will be off by about 8 square meters in most cases.
PS: We applied the same process to data from https://baania.com/ and it was a success!
Update 2022-07-14: Baania now has opendata! Check it out at https://gobestimate.com/data.