Visualizing map region prefix/suffix
import geopandas as gpd
import geoplot as gplt
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from geoplot import polyplot
from pythainlp.tokenize import syllable_tokenize, word_tokenizeData structure
- name: target region name
- geometry: spatial column
- *: parent region name, e.g. in "district" dataset it would have a "province" column
Dissolving dataset in case you have multiple region level in the same file
## assuming you have a district dataset and want to dissolve to province only
district_filename = "FILE_PATH_HERE"
gdf = gpd.(district_filename)
used_columns = [
"province",
"district",
]
gdf = gdf.(
columns={
"prov_namt".(): "province", # change to dummy
"amp_namt".(): "district",
}
)
gdf = gdf[used_columns + ["geometry"]]
## desired data 🛎🛎🛎 please do create a datasest with outermost region, so we can use it as boundary for visualization
province = gdf.(by="province")
province = (
province.().(columns={"province": "name"}).(columns="district")
)
province| name | geometry | |
|---|---|---|
| 0 | กระบี่ | MULTIPOLYGON (((99.14285 7.57282, 99.14256 7.5... |
| 1 | กรุงเทพมหานคร | POLYGON ((100.51756 13.66185, 100.51754 13.661... |
| 2 | กาญจนบุรี | POLYGON ((99.76845 14.09449, 99.76898 14.09458... |
| 3 | กาฬสินธุ์ | POLYGON ((103.54900 16.21370, 103.54763 16.213... |
| 4 | กำแพงเพชร | POLYGON ((99.97734 16.11070, 99.97546 16.10861... |
| ... | ... | ... |
| 71 | เพชรบุรี | POLYGON ((100.02689 12.91666, 100.02690 12.916... |
| 72 | เพชรบูรณ์ | POLYGON ((101.30859 15.57351, 101.30821 15.566... |
| 73 | เลย | POLYGON ((102.01428 17.14017, 102.01439 17.140... |
| 74 | แพร่ | POLYGON ((99.64157 18.05575, 99.64237 18.05561... |
| 75 | แม่ฮ่องสอน | POLYGON ((98.16045 18.15059, 98.16069 18.15037... |
76 rows × 2 columns
## declare dummy variable so it can be reused with other region type
df = provinceEDA: tokenize region name. Use other tokenizer for your target language
def tokenize(unique_region_values):
"""
input: unique values of region type
return: dataframe with token columns
"""
temp = pd.()
temp["name"] = pd.(unique_region_values)
temp["token"] = temp["name"].(lambda x:(x))
# Thai doesn't use space to separate words, so it's a bit wonky
# when I tell it to do such, that's why I need to see the results
# manually, and in some cases it may "clip" a token
temp["token_1-1"] = temp.token.str[0]
temp["token_1-2"] = temp.token.str[1]
temp["token_1_full"] = temp["token_1-1"] + temp["token_1-2"]
temp["token_2-1"] = temp.token.str[-2]
temp["token_2-2"] = temp.token.str[-1]
temp["token_2_full"] = temp["token_2-1"] + temp["token_2-2"]
return tempDon't forget to look through the results and pick tokens you think are "correct"
(df.name.())| name | token | token_1-1 | token_1-2 | token_1_full | token_2-1 | token_2-2 | token_2_full | |
|---|---|---|---|---|---|---|---|---|
| 0 | กระบี่ | [กระ, บี่] | กระ | บี่ | กระบี่ | กระ | บี่ | กระบี่ |
| 1 | กรุงเทพมหานคร | [กรุง, เทพ, มหา, นคร] | กรุง | เทพ | กรุงเทพ | มหา | นคร | มหานคร |
| 2 | กาญจนบุรี | [กาญ, จน, บุ, รี] | กาญ | จน | กาญจน | บุ | รี | บุรี |
| 3 | กาฬสินธุ์ | [กาฬ, สินธุ์] | กาฬ | สินธุ์ | กาฬสินธุ์ | กาฬ | สินธุ์ | กาฬสินธุ์ |
| 4 | กำแพงเพชร | [กำ, แพง, เพชร] | กำ | แพง | กำแพง | แพง | เพชร | แพงเพชร |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 71 | เพชรบุรี | [เพชร, บุ, รี] | เพชร | บุ | เพชรบุ | บุ | รี | บุรี |
| 72 | เพชรบูรณ์ | [เพชร, บูรณ์] | เพชร | บูรณ์ | เพชรบูรณ์ | เพชร | บูรณ์ | เพชรบูรณ์ |
| 73 | เลย | [เลย] | เลย | NaN | NaN | NaN | เลย | NaN |
| 74 | แพร่ | [แพร่] | แพร่ | NaN | NaN | NaN | แพร่ | NaN |
| 75 | แม่ฮ่องสอน | [แม่, ฮ่อง, สอน] | แม่ | ฮ่อง | แม่ฮ่อง | ฮ่อง | สอน | ฮ่องสอน |
76 rows × 8 columns
Tokenize with selected slugs
## replace with your slugs here
slugs = ["นคร", "สุ", "สมุทร", "ธานี", "นคร"]
slugs = sorted(list(set(slugs)))
slugs = slugs[::-1] # for longest matching
## get prefix and suffix
def get_slug_1(x):
for i in slugs:
if x.(i):
return i
def get_slug_2(x):
for i in slugs:
if x.(i):
return idf["prefix"] = df["name"].(lambda x:(x))
df["suffix"] = df["name"].(lambda x:(x))
df| name | geometry | prefix | suffix | class | |
|---|---|---|---|---|---|
| 0 | กระบี่ | MULTIPOLYGON (((99.14285 7.57282, 99.14256 7.5... | None | None | class |
| 1 | กรุงเทพมหานคร | POLYGON ((100.51756 13.66185, 100.51754 13.661... | None | นคร | class |
| 2 | กาญจนบุรี | POLYGON ((99.76845 14.09449, 99.76898 14.09458... | None | None | class |
| 3 | กาฬสินธุ์ | POLYGON ((103.54900 16.21370, 103.54763 16.213... | None | None | class |
| 4 | กำแพงเพชร | POLYGON ((99.97734 16.11070, 99.97546 16.10861... | None | None | class |
| ... | ... | ... | ... | ... | ... |
| 71 | เพชรบุรี | POLYGON ((100.02689 12.91666, 100.02690 12.916... | None | None | class |
| 72 | เพชรบูรณ์ | POLYGON ((101.30859 15.57351, 101.30821 15.566... | None | None | class |
| 73 | เลย | POLYGON ((102.01428 17.14017, 102.01439 17.140... | None | None | class |
| 74 | แพร่ | POLYGON ((99.64157 18.05575, 99.64237 18.05561... | None | None | class |
| 75 | แม่ฮ่องสอน | POLYGON ((98.16045 18.15059, 98.16069 18.15037... | None | None | class |
76 rows × 5 columns
Viz prep
## make total_bound (background outline)
## and extend (so the canvas would center at the same point)
## also, remember the PROVINCE dataset from the start? we're going to use that
province["class"] = "class" # a dummy column so it would dissolve the whole dataset
boundary = province.(by="class")
extent = boundary.total_bounds## set font (default matplotlib font can't render Thai)
plt.rcParams["font.family"] = "Tahoma"Cleaning it up
There are some degree of Pali-Sanskrit influence in Thai, in which the word order is different, so it is possible for a certain *fix to appear as either prefix or suffix. it's like repeat and dore (for redo)
## ⛩⛩⛩ rerun from this cell onward if you want to change *fix ⛩⛩⛩
## filter null *fix
_fix_column = "suffix" # ⛩⛩⛩ change here ⛩⛩⛩
df_temp = df
df_temp = df_temp[df_temp[_fix_column].()]
## get count
df_temp["{}_count".(_fix_column)] = df_temp[_fix_column].(
df_temp[_fix_column].().()
)## at the largest region level it won't be much, but at a smaller level like subdistrict
## having a single *fix for the entire dataset can happen, hence we should filter it out
## filter for a *fix you want to visualize
viz_categ_count_column = "{}_count".(_fix_column)
## ⛩⛩⛩ use the second line if you want to set the threshold with median ⛩⛩⛩
threshold = 0
## threshold = df_temp[viz_categ_count_column].median()
df_temp = df_temp[df_temp[viz_categ_count_column] >= threshold]df_temp| name | geometry | prefix | suffix | class | suffix_count | |
|---|---|---|---|---|---|---|
| 1 | กรุงเทพมหานคร | POLYGON ((100.51756 13.66185, 100.51754 13.661... | None | นคร | class | 2 |
| 25 | ปทุมธานี | POLYGON ((100.91417 13.95445, 100.91415 13.952... | None | ธานี | class | 5 |
| 48 | สกลนคร | POLYGON ((104.36246 17.09941, 104.36248 17.099... | None | นคร | class | 2 |
| 58 | สุราษฎร์ธานี | MULTIPOLYGON (((99.20865 8.33715, 99.20647 8.3... | สุ | ธานี | class | 5 |
| 64 | อุดรธานี | POLYGON ((103.44196 17.21428, 103.44246 17.214... | None | ธานี | class | 5 |
| 66 | อุทัยธานี | POLYGON ((100.04080 15.29612, 100.04067 15.296... | None | ธานี | class | 5 |
| 67 | อุบลราชธานี | POLYGON ((105.55486 14.95406, 105.55414 14.953... | None | ธานี | class | 5 |
Viz
import os
key_column = _fix_column
key_name = "province" # ⛩⛩⛩ set region type here #
key_count_column = "{}_count".(key_column)
out_dir = "plot/{}_{}".(key_name, key_column)
os.(out_dir, exist_ok=True)
gdf = df_temp
for key in gdf[key_column].():
ax = gplt.(boundary, figsize=(10, 15))
query = gdf[gdf[key_column] == key]
total_records = str(int(query[key_count_column].()[0]))
gplt.(query, ax=ax, extent=extent, edgecolor="black", facecolor="green")
plt.("{}: {} records".(key, total_records))
plt.("{}/{}_{}.png".(out_dir, str(total_records).(3), key))
## breakOutput structure
Some interesting outputs (at subdistrict level)
Northern region
You can see that the prefix "แม่" concentrates around the northern region. 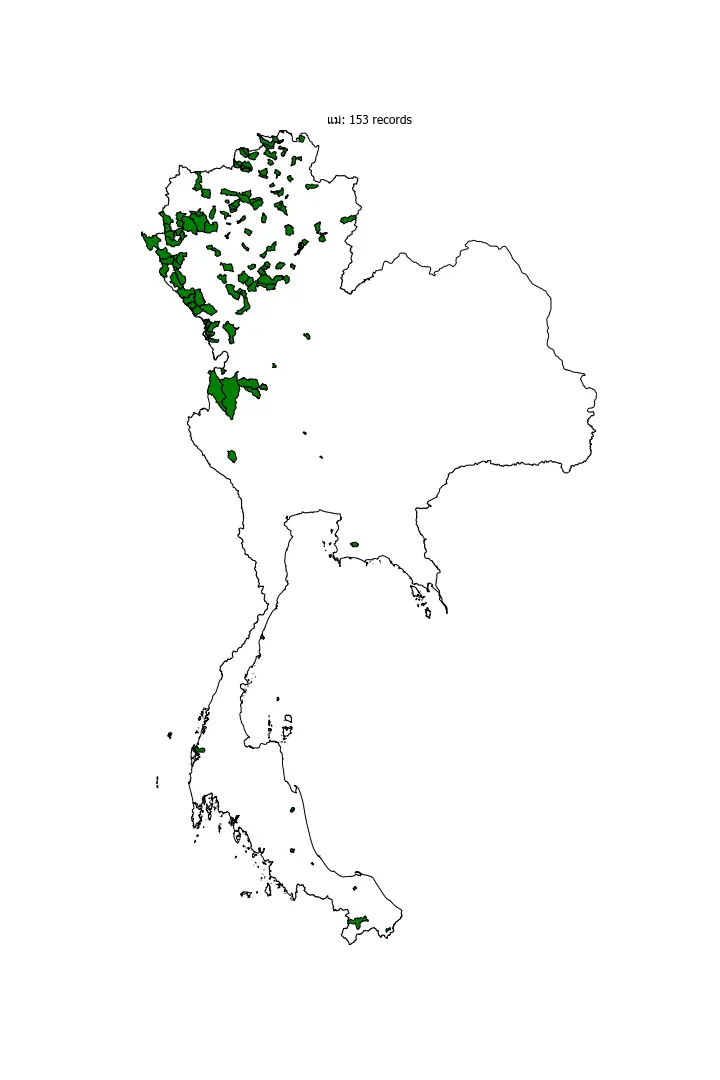
Eastern region
"โนน" seems to be specific to the eastern seeing it's clustered around the eastern part of the country. 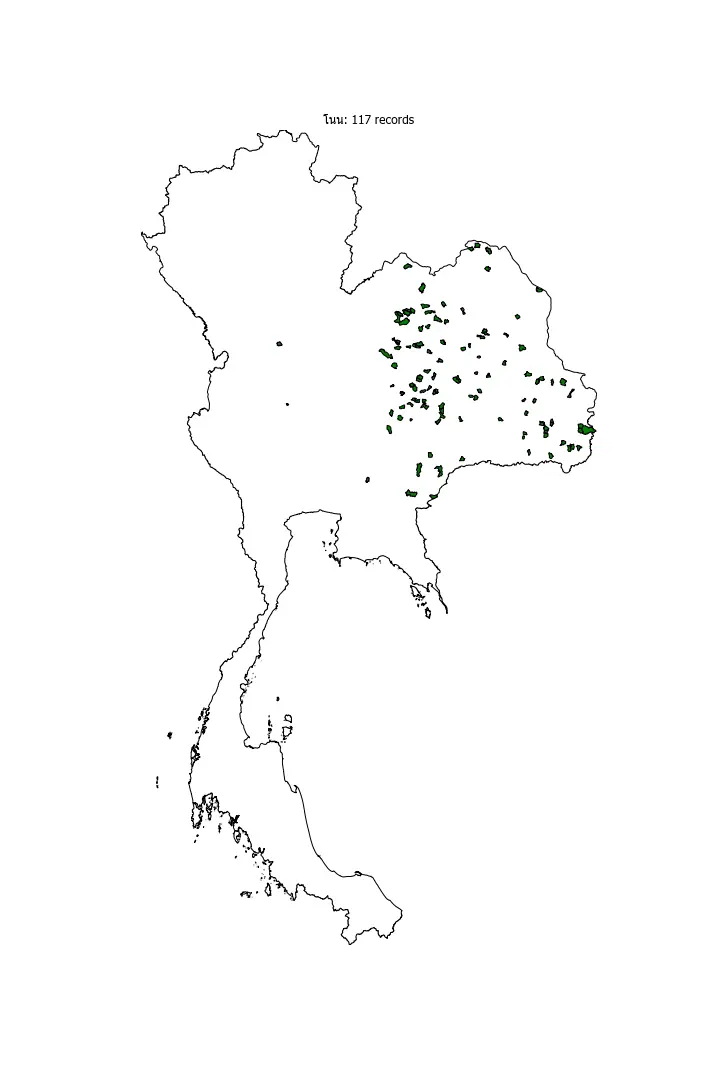
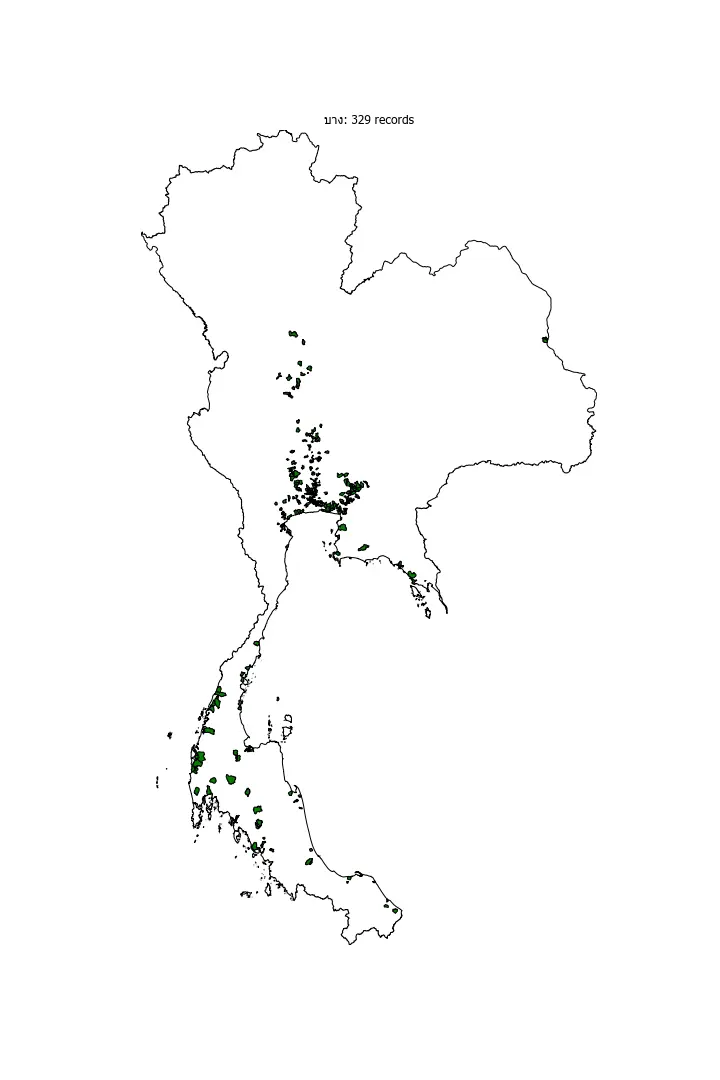
Multi-region
As expected, "บาง" is clustered around the central region, no surprise here since the old name of Thailand's capital (it's located in the central region) is "บางกอก." But you can see that it's clustered around the southern parts as well.