Dataframe processing benchmarks
ภาษาไทย

Given the rise of duckdb and polars in recent years, in addition to parquet format being more widely adopted for data storage format, it might be a good time to see how source data format affects data processing speed - in addition to the framework choice.
Processing 1 Million Rows
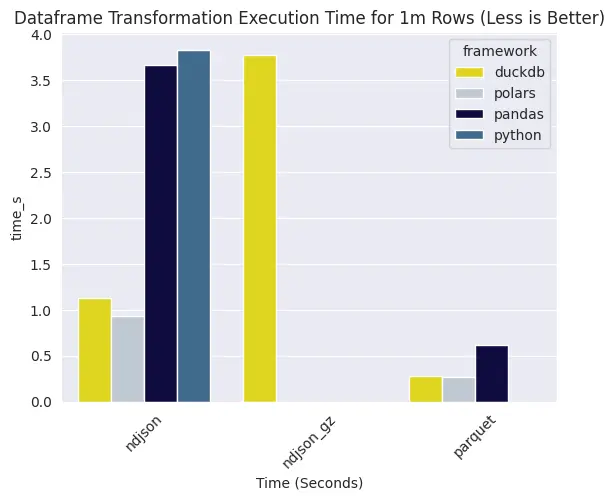
For a simple transformation (colNew = colA/colB), it is obvious that when source format is parquet, it takes the least time to process the data.
With ndjson, also known as single-line json, it usually comes into two variants: uncompressed and compressed. At the time of writing this article, polars can't read gzipped ndjson directly, but duckdb can. It's evident that by processing gzipped ndjson, it takes a lot more time compared to uncompressed ndjson for duckdb.
Unsurprisingly, pandas takes significantly longer than duckdb and polars when it comes to reading ndjson.
However, it should be of note that given 1 million rows, polars is faster than duckdb when it comes to parsing ndjson, but for parquet, it's almost a tie.
As for pure python for comparison - which took longest to execute, it's running a simple for-loop for a readlines stream. I wouldn't recommend using a for-loop for processing data, but I've seen a few in production - in which I would recommend you to migrate to polars or whichever dataframe framework you prefer as soon as possible, because it's a ticking time bomb for all things that could go wrong - and failing pipelines would be the least of your worries. Hint: the revenge of data types.
Interestingly enough, reading parquet via pandas results in significantly faster processing speed, so if you really need to use pandas, working with parquet can improve execution performance - but at certain point migrating off to polars/duckdb/spark might be better in the long run.
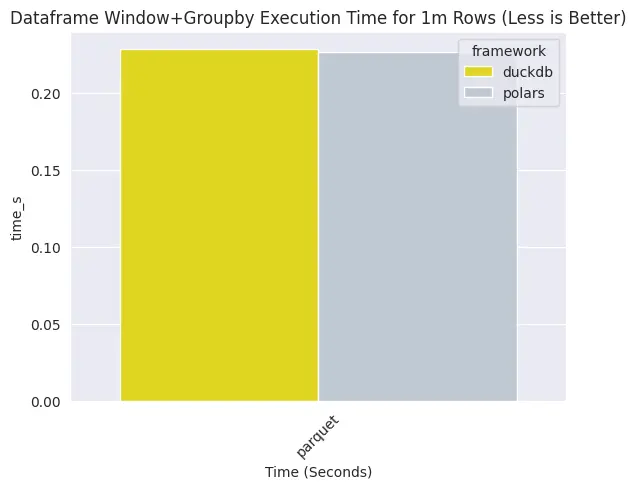
As for a window+groupby aggregation, at 1 million rows, it's almost a tie, but polars takes slightly less time.
Now, to crank it up a notch...
Processing 50 Million Rows
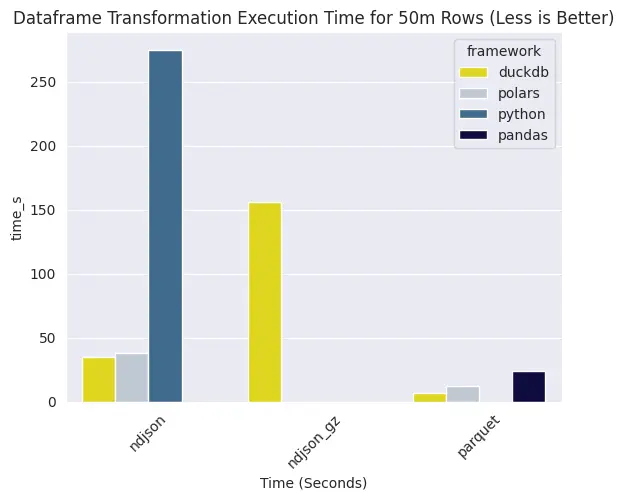
At this point, pandas struggles to parse 50m rows of ndjson, but interestingly, polars takes longer to run compared to duckdb for both ndjson and parquet.
Also take note that given 50 million rows, having parquet as source in duckdb results in 6x faster execution time compared to ndjson. As for polars, parquet can give a 3x performance boost in relation to ndjson as source.
But not so fast, because if we are talking about window+groupby aggregation:
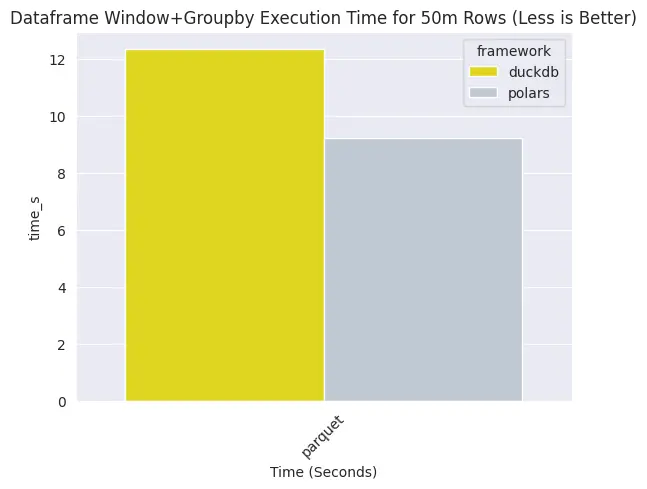
polars takes less time than duckdb.
The claim that duckdb is faster than polars is true. But another conflicting claim that polars is faster than duckdb is also true.
Given the amount of data to process and performed operations, for a simple transformation, duckdb is faster than polars - at 50 million rows this translates to duckdb being 2x faster than polars.
But if we are talking about heavy-duty aggregations, polars is faster than duckdb.