Dataframe processing benchmarks (ภาษาไทย)
English

ช่วงหลังๆ มานี้ duckdb กับ polars มาแรงขึ้นเรื่อยๆ พ่วงมากับการที่ parquet เป็นที่นิยมมากขึ้นในการใช้เก็บข้อมูล เลยว่าเป็นฤกษ์ดีในการมาดู ว่า data format กับ framework จะมีผลกับความไวในการปั่นข้อมูลขนาดไหน
Processing 1 Million Rows
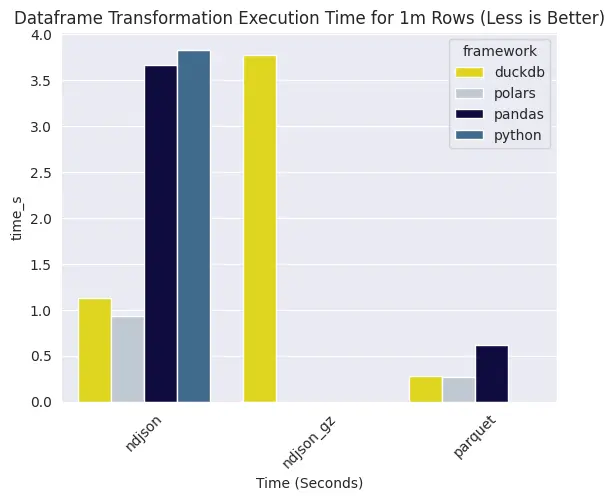
สำหรับการ transform ข้อมูลแบบง่ายๆ (colNew = colA/colB) ค่อนข้างชัดว่า ถ้าอ่านเป็น parquet จะใช้เวลาน้อยสุดในการปั่น
ถ้าเป็น ndjson หรือที่เรียกกันอีกชื่อว่า single-line json ส่วนมากจะโผล่มาสองแบบ: แบบ plaintext กับแบบที่เอาไปห่อไว้ใน gzip อีกที ตอนที่เขียนบทความนี้ polars ยังไม่สามารถอ่าน gzipped ndjson ตรงๆ ได้ แต่ duckdb ทำได้ ซึ่งก็ค่อนข้างเห็นได้ชัดว่าถ้าให้ duckdb ไปอ่าน gzipped ndjson จะใช้เวลานานกว่าถ้าเทียบกับการอ่าน plaintext ndjson แบบปกติ
แต่ก็ไม่แปลกใจที่ pandas จะใช้เวลานานสุดถ้าต้องอ่าน ndjson
มวยอ่านข้อมูล 1 ล้านแถว ถ้าเทียบกันยังไง polars ก็ไวกว่า duckdb แต่ถ้าเป็น parquet ก็จะสูสีกันหน่อย
สำหรับการใช้ python แบบไม่ผ่าน framework ปั่นข้อมูล ก็ถือว่าใช้เวลานานสุด เป็น for-loop ธรรมดาที่ต่อจาก readlines stream อีกที จริงๆ ไม่ค่อยแนะนำให้ใช้ for-loop แต่ก็เคยเห็นใน production อยู่ อยากแนะนำให้เปลี่ยนไปใช้ dataframe framework ตัวไหนก็ได้ที่สะดวก เพราะว่ามันจะเป็นระเบิดเวลา จะมีโอกาสพังเยอะ จนถึงตอนนั้น pipelines พังไม่ค่อยน่ากลัวเท่า data types พังแล้วต้องไปไล่ซ่อม
แต่ก็น่าสนใจตรงที่ ถ้าจับ pandas มาอ่าน parquet ก็ลดเวลาปั่นไปได้เยอะ ก็คือถ้าจำเป็นต้องใช้ pandas แล้วเลี่ยงไม่ได้ การอ่านไฟล์ต้นทางเป็น parquet จะช่วยได้ในเรื่องของความเร็วในการทำงาน แต่ถึงจุดนึงย้ายไปใช้ polars/duckdb/spark จะยั่งยืนกว่าในระยะยาว
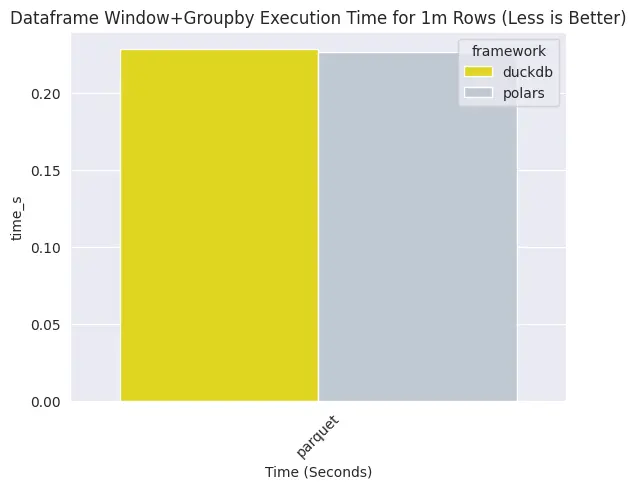
ในส่วนของการทำ window+groupby หนักๆ สำหรับ 1 ล้านแถว ความเร็วไม่ค่อยต่างกันมาก แต่ polars จะไวกว่านิดหน่อย
เอาล่ะ ได้เวลาเร่งเครื่อง...
Processing 50 Million Rows
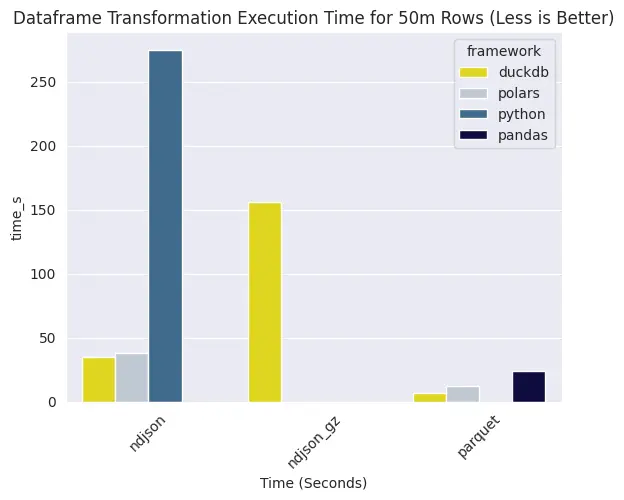
ณ จุดนี้ pandas อ่าน ndjson 50 ล้านแถวไม่รอด แต่น่าสนใจตรงที่ polars ใช้เวลานานกว่าถ้าเทียบกับ duckdb ในการอ่านไฟล์จากทั้ง ndjson และ parquet
ที่เด่นจริงๆ คือ การที่ไฟล์ต้นทางเป็น parquet ทำให้ duckdb ใช้เวลาไวขึ้น 6x ถ้าเทียบกับอ่านจาก ndjson สำหรับ polars เอง การอ่านไฟล์เข้ามาจาก parquet ก็ทำให้ปั่นไวขึ้น 3x เทียบกัน ndjson
แต่ยังไม่จบ เพราะว่า ถ้าไปมวยต่อไป คือ window+groupby:
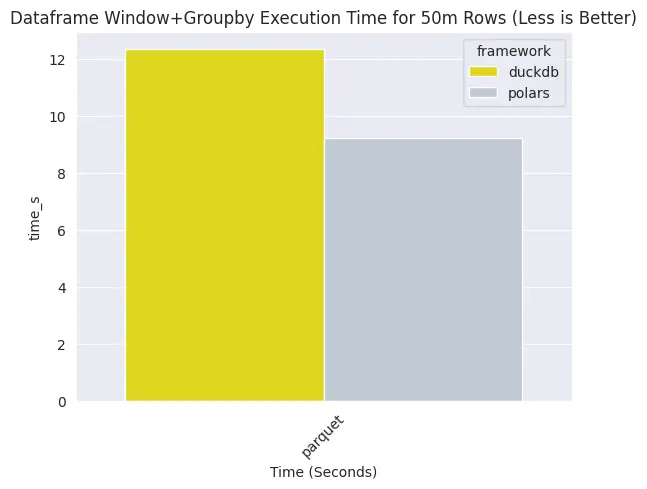
polars ไวกว่า duckdb
คนเขาบอกว่า duckdb ไวกว่า polars ก็จริง แต่ขั้วตรงข้ามที่บอกว่า polars ไวกว่า duckdb ก็จริง
ถ้าเทียบกันกับจำนวนแถวที่ต้องปั่นและท่าละเลงข้อมูล ถ้าเป็นอะไรง่ายๆ duckdb จะไวกว่า polars ก็คือถ้ามี 50 ล้านแถว duckdb จะไวกว่า polars สองเท่า
แต่ถ้าละเลงหนักๆ แบบมาทั้ง window + groupby จะเป็น polars ไวกว่า duckdb