Spatial join performance
In a community I'm in, someone asked how to optimize a slow spatial join query. There are multiple approaches, but the general idea is to reduce the resulting set (setA would be your polygons, setB would be your points) from a join operation (hello set theory).
Tools & Frameworks Used
- DataFusion
- DuckDB
- Pandas (via GeoPandas)
- Polars
- PostGIS
- Spark (via Sedona)
Note that while DuckDB has H3 extension, the implementation is still wonky - it doesn't always return values.
As for polars, its spatial ecosystem is still in its infancy. Additionally, I/O is backed by GeoPandas, which is slower than polars proper, so it can results in parsing bottleneck.
As for DataFusion, there is no spatial support yet.
Experiment Design
A spatial join operation (point-in-polygon) would be performed via native spatial functions, and via H3 index. Source data is in (geo)parquet, except for PostGIS where data is pre-loaded into a table. Compute is Macbook Pro M3 (16 GB RAM).
H3 index is a spatial index created by Uber. The important thing is that if you utilize H3 index properly, you can perform spatial operations in any languages even when they don't support spatial operations.
Specifically for point-in-polygon, you would have two spatial datasets: boundary polygons and points. H3 index for each dataset would be created - in which the boundary dataset would return a set of H3 cell ids, and the points dataset would return a single H3 cell id. Then, it's a matter of filtering your dataset after a join to find the intersection.
H3 index has multiple levels of resolution. In this experiment, H3 index resolution is set to 7 (around 5.16 KM2 area per cell).
Note that for H3 experiment, the cell ids are pre-calculated. This is because generating H3 cell ids is an expensive operation (so far given the size of dataset used, only spark can successfully generate H3 cell ids and not crash in the process).
Results
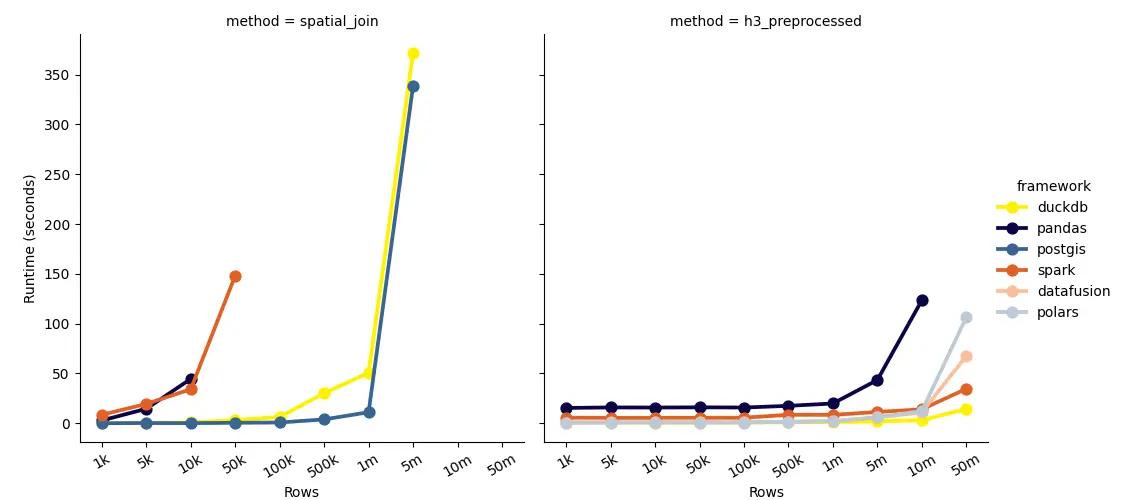
Notice the sharp hikes, it means the performance reaches a bottleneck. Going further would mean exponential runtime.
Native Spatial Join
For spatial join, note that pandas at 50k rows results in exit 137 error - meaning it ran out of memory.
DuckDB and PostGIS have very similar performance, but PostGIS is slightly faster. However, factoring in data loading into PostGIS would mean it's not as economical compared to using DuckDB, which can read data from files on-the-fly. Computation-wise, they are the most performant.
Spark elbows at 50k rows, which means the underlying spatial engine (sedona) is not as optimized for spatial operations. Further data prep and pre-processing is required to optimize the performance.
Geopandas has similar performance to spark, but at 50k rows it ran out of memory, whereas spark is still manageable.
For all native spatial join operations, no frameworks can process further than 5 million rows without running into memory issues.
H3
Note that the join operation is not a cross join, rather it's a normal join where a=b. Specifically, boundary dataset containing H3 cell ids column is exploded into multiple rows, one for each cell id.
This method can process up to 50 million rows, albeit with slightly less accuracy due to the nature of H3 index. Then again, in big data world, you might need to sacrifice accuracy for performance.
But pandas being pandas, it can't process further than 5 million rows.
DuckDB is faster than polars, but this is because there is no calculation or aggregation done at runtime, in which polars would be more efficient if it's were the case. Surprisingly, DuckDB is the fastest, surpassing even DataFusion (which is written in Rust).
What really surprised me is that spark is faster than polars and DataFusion. Which is to say given certain scale things might turn around.
In all, DuckDB and spark are the fastest. Slightly slower are polars and DataFusion, both are Rust-based. Whereas pandas is slowest - processing 5 million rows in pandas takes about the same time as processing 10 million rows in polars.
Conclusion
If you have a small dataset, any method should work, bonus if your framework supports spatial operations. However, at more than 10k rows, you can get by with DuckDB up until 1 million rows, which then it would be hard to scale.
At this point, utilizing H3 index would be more economical, even pandas can process up to 10 million rows. But more than that spark would scale best, since it is a distributed engine. While DataFusion has Ballista, it is still quite tricky to get it up and running, in which your engineering time is better spent on something else.
However, you still need to somehow pre-calculate the H3 index. Given a large dataset and H3 support, only spark fits the bill. At the end of day, you still need spark.
But you can also use Snowflake or something else that has H3 support to pre-calculate the H3 index, but then it would be best if you use your data warehouse to perform spatial join, since this means you don't have to move data around.